AI人工智能这几年作为科技界的热门话题被媒体宣传的如火如荼。在这种氛围之下,身为创客的我们怎能错过展现好点子落地的大好时机呢?接下来就为大家介绍如何取得及应用免费的AI实验场域资源「Google Colaboratory」。
Google免费GPU资源Colaboratory
大家都说要玩AI先得准备个很贵的高级显卡及服务器才能跑得动,对于想入门练练手的人实在有点花不下去,就像想学开车的人不会先买一台法拉利,而是先去教练场学到一定程度后,再考虑一下预算及需求后才会依用途去买合适的跑车、房车、货车、代步车甚至是二手车。
现在阮囊羞涩的各位有福了,Google旗下的实验计划Colaboratory (以下简写为Colab)提供了免费的NVIDIA K80等级GPU资源及虚拟机(Xeon 2.2GHz CPU*2)供大家使用,其中整合了Linux (Ubuntu)环境、Python、Jupyter notebook及TensorFlow等常用套件包,并允许大家安装执行时所需套件包(如Keras、 OpenCV、PyTorch、MxNet、XGBoost等),只要有Google云端硬盘账号就可免费使用。

Google Colaboratory
当然不可避免地,这项免费资源并非毫无使用限制的,所提供的虚拟服务器,目前只提供至少50G储存空间和12GB(可用于训练约2GB)的内存,使用时间仅可连续12小时(包含安装软件套件包、数据下载到虚拟机及训练时间)。超过时间便会清掉使用中内容,有时还会因使用者过多造成连不上线或用到一半断线,并不适合用在太大的模型及数据集训练。
话虽如此,整体来说还是很方便家中没有Linux + Python环境或计算机(笔电)CPU等级太低或没有独立显卡的人及想学习人工智能的新手练习使用。
何谓影像二元分类
在知名HBO影集「硅谷群瞎传」第四季的第四集当中有个有趣的桥段,华人杨靖发明一款可拍照后辨识食物类型的APP叫「See Food」,展示时第一次拍热狗成功辨识,众人欢呼开始想象满桌子的食物若都能辨识出来的话,这款APP肯定大卖。接着再拍了披萨后众人等着APP回答「披萨」,可是APP却回答「不是热狗(Not Hotdog)」,众人瞬间傻眼,「这只能辨识热狗吗?」杨靖回答:「是」,众人大失所望、一哄而散。
然而,故事还没完呢!竟有一家创投看上这个APP,要他改成侦测色情图片中男生的小丁丁,这就是标准的「失之东隅,收之桑榆」。
虽然上面桥段的「Not Hotdog」只是虚构剧情,但现实中还真的人有把它实现出来,有兴趣的人可到Apple APP Store下载Not Hotdog 。从上面故事中我们可得知影像分类的重要性,虽然影像二元分类(是或不是)的用途较窄些,但若能大量(数千到数百万张)标注影像的分类,经过训练后可令影像精准地分类,那就有可能产生一些独特的商机。

Not Hotdog APP屏幕撷图
用Colab实现影像二元分类
为了让大家能快速上手,在此整理了一段完整的代码并有详尽的原理解说及批注,只要依着下列步骤就可快速建构出一个二元分类的影像分类系统,当然也包括如何用自定义的数据集进行训练及推论。代码主要包括以下四个主要步骤,另外还有更进一步的细节说明,如下所示。
1. 取得及建构训练数据(TrainingDataset)
下载数据集
数据集解压缩
检视数据集
自定义数据集及挂载
2. 建构一小型深度学习模型(TrainingModel)
卷积网络模型
输入图像尺寸正规化
模型架构及训练参数说明
模型配置及训练优化设定
数据预处理
3. 训练及验证模型准确度(ValidationAccuracy)
训练及验证模型
评估模型的准确性和损失
4. 应用深度学习训练成果进行推论(Inference)
推论
可视化表示
了解了相范例的学习目标后,可以至https://goo.gl/SqigfE下载image_classification.ipynb 到您的Google云端硬盘,双击后选择以「Colaboratory」开启,就可以开始享受Colab提供的免费GPU运算信息。执行时,请按【Shift+Enter】进行单步执行并自动跳至下一行;若想一次全部运行本范例所有代码,可按【Ctrl+F9】。接下来就简单为大家介绍主要步骤的工作内容。
建构数据集
为了练习「建构数据集」这个题目,我们首先必须要有数据集,但实在不容易在短时间内收集到数千张的影像,好在知名人工智能比赛平台Kaggle上有一个「Dogs and Cats」的影像分类比赛,它提供了大量的猫狗影像,以供测试「深度学习」算法(模型)的正确性。
Google为方便大家测试Colab,再将其减量到训练用影像猫狗各1000张,验证用影像猫狗各500张,其数据集样本大致上如下图所示。影像没并没有特定尺寸,猫狗在影像中占的面积比例、种类、色彩、数量、位置、明暗、遮蔽、背景复杂度也都没有限制。

Kaggle提供的「Dogs and Cats」数据集样本
卷积神经网络模型
这个范例中,主要利用TensorFlow及Keras建构出一个小型的卷积神经网络(Convolution Neural Network, CNN),共有三层卷积层(包含ReLu及Max Pooling),每个卷积层皆用3×3的滤波器进行卷积动作,三层分别提取16, 32及64组滤波器。接着展开成独立节点后,再加入二层全连结层,分别为512及1个节点,而最后得到的那一个节点加上Sigmodid函数即为最终输出的结果,合计共有9,494,561个参数待训练。
输出的结果值会介于0.0 ~ 1.0,当值越接近1.0时图片为狗的机率越高,反之输出值越接近0.0时图片判定是猫的机率越高。虽然这个模型虽然不大,但可适用各种图像的二元分类问题,大家可试着导入自己准备的图像进行测试。完整模型架构可参考下图。
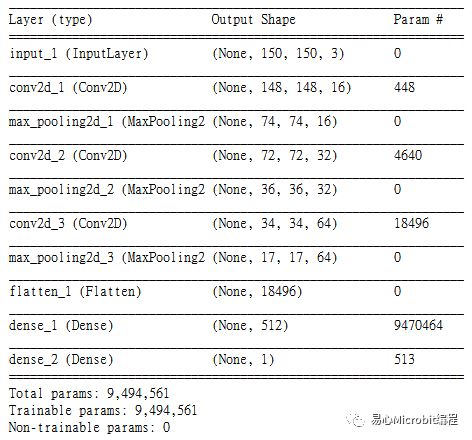
卷积神经网络架构
训练及验证
下方图左为正确率,图右为损失率,横轴代表迭代次数,纵轴代表正确(或损失)率;蓝线代表训练集结果,而绿线代表验证集结果。从图中可看出蓝线在第十次正确率就已超过0.97(97%),而损失率已趋近0,但绿色的线正确率却没有继续变高,数值约接近0.7(70%),损失率反而逐渐增高。这表示训练过程已造成过拟合(over fitting)的状况,需要加入更多不同样态及更多数量的数据集再重新训练才能改善。
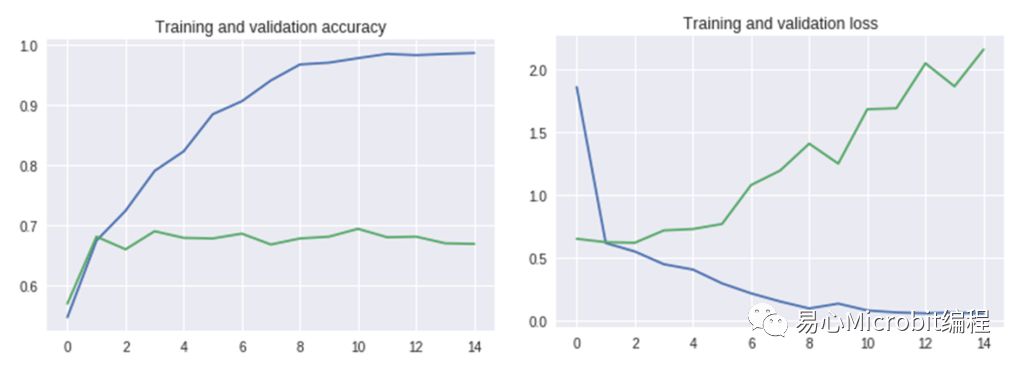
左:训练及验证准确性,右:训练及验证损失
推论结果
接着就可利用前面训练好的模型(model)来加以推论(或称为预测)。首先提供一张图片,并将图像数据正规化(150x150x3, Float32),接着进行推论,最后会得到图像分类结果分数,而分数越接近1.0则表示是狗的机率越高,反之越接近0.0则越可能是猫。我们可以另设几个自定义门坎值来区隔分类结果,比方说「这是狗」、「这可能是狗」、「这可能是猫」、「这是猫」等不同结果描述。
为了让大家更了解深度学习模型运作方式,将各层运作结果输出到特征图中,再逐一秀出。如下图,最上面为原始输入影像正规化后的结果图,再来才是真正导入输入层的信息,尺寸为150×150共有3组(RGB三通道)。
第一卷积层共产生16个特征图,conv2d_1尺寸为148×148,max_pooling2d_1尺寸为74×74;第二卷积层共产生32个特征图,conv2d_2尺寸为72×72,max_pooling_2为36×36;第三卷积层共产生64个特征图,conv2d_3尺寸为34×34,max_pooling_3为17×17;最后的全连结层(dense)则为单一节点信息,不易以图形方式表示,故忽略不处理。
从各层特征图中可看出,随着影像尺寸缩小其被激活的像素越来越少,甚至完全不输出(全黑),表示其特征已被某些卷积(滤波器)给凸显出来。对于我们所需的图像分类(辨识)能力也逐渐增强了。
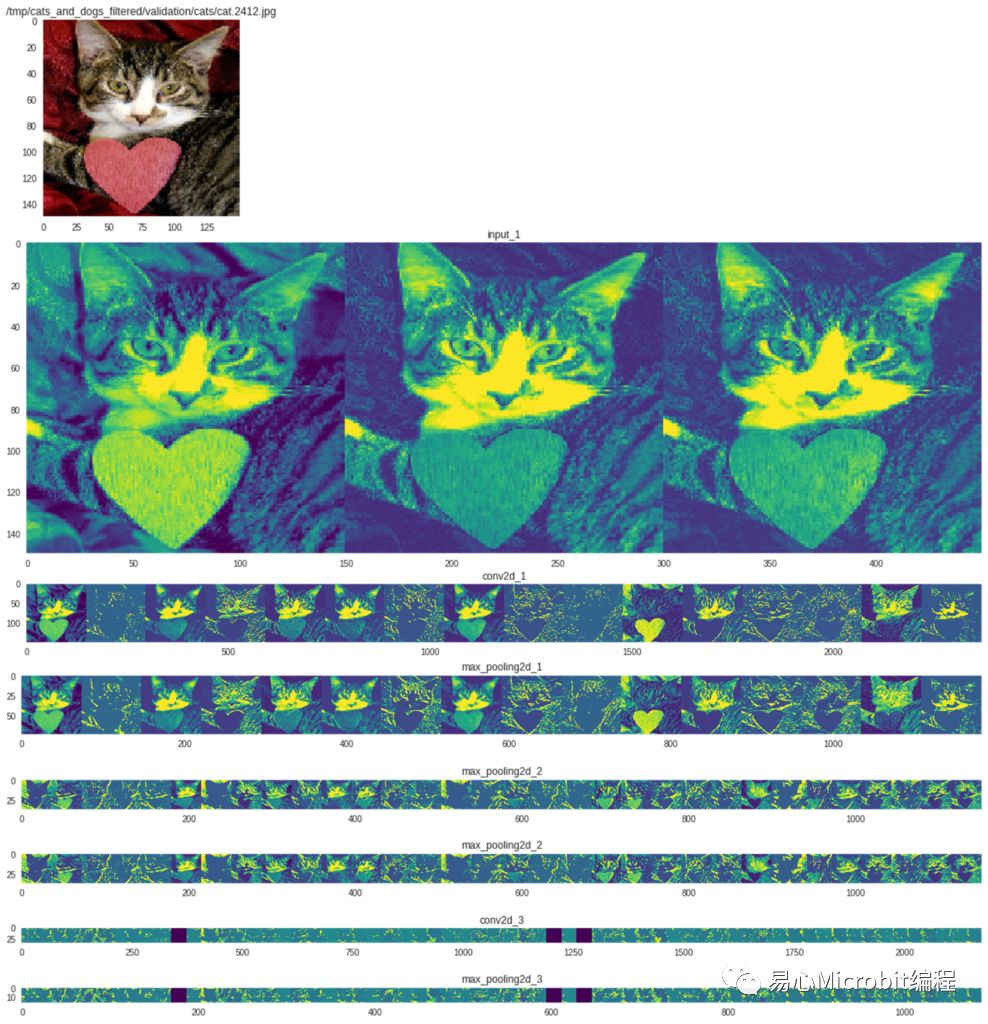
推论结果可视化
结论
Google Colaboratory这项免费的云端GPU资源实在很方便刚入门的伙伴进行「深度学习」(一语双关),它不会因为个人计算机(笔电)的配备等级不同,而影响模型训练及推论的效能。同时,可轻易的分享代码给其它想学的人,对开源社群更是一大助力。希望不久的将来有更多伙伴能一起加入研究及分享,让更多人工智能的应用能加速落地。
完整代码及说明,请参阅Github.
作者:许哲豪
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。